
ChatGPT and other language models are here to stay.
But using these models is not enough. You also want to know how they work.
Here is an introduction to the fundamental building block behind these models: word embeddings.
The internet is mostly text.
For centuries, we've captured most of our knowledge using words.
Unsurprisingly, many companies are racing to build models that process and distill this knowledge. ChatGPT and Bard are only the latest examples.
But there's one fundamental problem:
Contrary to people, computers don't work well with text.
To build a model capable of distilling meaning out of language, we needed to find a way to turn words into numbers.
This is more difficult than you think:
A simple, intuitive solution is to replace each word with an arbitrary number.
For example, here are four words and their corresponding numerical values:
• King → 1
• Queen → 2
• Man → 3
• Woman → 4
This simple indexing works, but it has a lot of problems.
Instead of using consecutive numbers, models work much better with vectors of 0's and 1's:
For example:
• King → [1, 0, 0, 0]
• Queen → [0, 1, 0, 0]
• Man → [0, 0, 1, 0]
• Woman → [0, 0, 0, 1]
We call this a "vector encoding," and here is the problem with it:
Our vocabulary has four words, but the Oxford English Dictionary says there are 171,476 words in current use!
Working with such large vectors would be a nightmare. To overcome this in practice, we only use 10,000 or 20,000 words.
On top of that, these vectors are dumb.
Intuitively, we know that a King and a Queen are related just like a Man and a Woman are.
But the simple vector encoding we are using doesn't help with that.
Here is where the idea of "word embeddings" come from.
A word embedding should have a simple characteristic:
Related words should be close to each other, while words with different meanings should lie far away.
How can we encode our four words in a way that makes this possible?
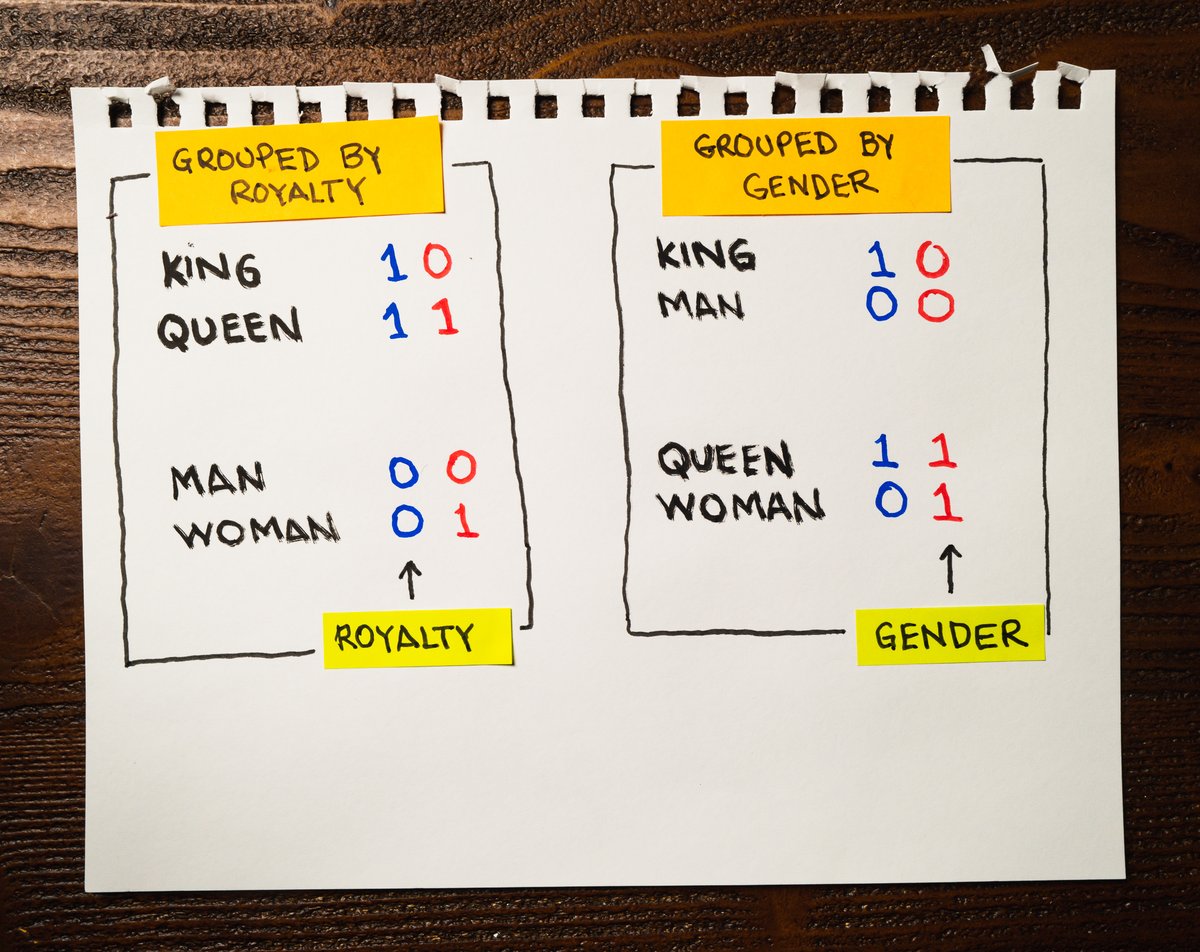
Look at the attached illustration with our four words.
This could be our new embedding:
• King → [1, 0]
• Queen → [1, 1]
• Man → [0, 0]
• Woman → [0, 1]
The pairs King/Queen and Man/Woman are now clearly related, but there is much more than that!

For simplicity, I used two dimensions to encode these words.
The horizontal dimension represents the concept of Gender: Going from left to right, you go from male to female.
And the vertical dimension represents the concept of Royalty.
Let's now look at the vectors:
The first component of our vectors indicates "Royalty." Both King and Queen have a value of 1.
The second component indicates "Gender." King and Man have a 0, while Queen and Woman have a 1.
This picture shows how we can group these words:
We can go beyond representing concepts in our word embedding and use geometric transformations to navigate between words!
For example, we can create an embedding where combining "King" and "Woman" will give us "Queen," and combining "Man" and "Queen" will give us "King."

I encoded my vocabulary in 2 dimensions.
But using more dimensions would allow me to represent more useful concepts besides Gender and Royalty.
The embeddings used by the models we use today can represent thousands of different concepts.
For example, @cohere's embeddings use 4,096 dimensions!
These embeddings have entirely changed the game.
An important thing to mention:
@cohere's embeddings, just like modern models, are sentence embeddings: They go beyond standalone words and encode entire sentences.
To understand how these embeddings change the game, here is one example:
Think about search.
Imagine you want to find every tweet that talks about movies. Instead of trying to match specific words, you could use embeddings.
A good word embedding should have the following words close to each other:
• Movie
• Film
• Screenplay
So you could simply compare the embedding of different words to return similar concepts!
Remember, they will be close to each other.
Isn't that cool?
We don't design word embeddings by hand.
Instead, we use machine learning to learn these embeddings.
Fortunately, we have access to many pre-trained word embeddings that we can use.
Here is how you can use a pre-trained word embedding using @cohere:
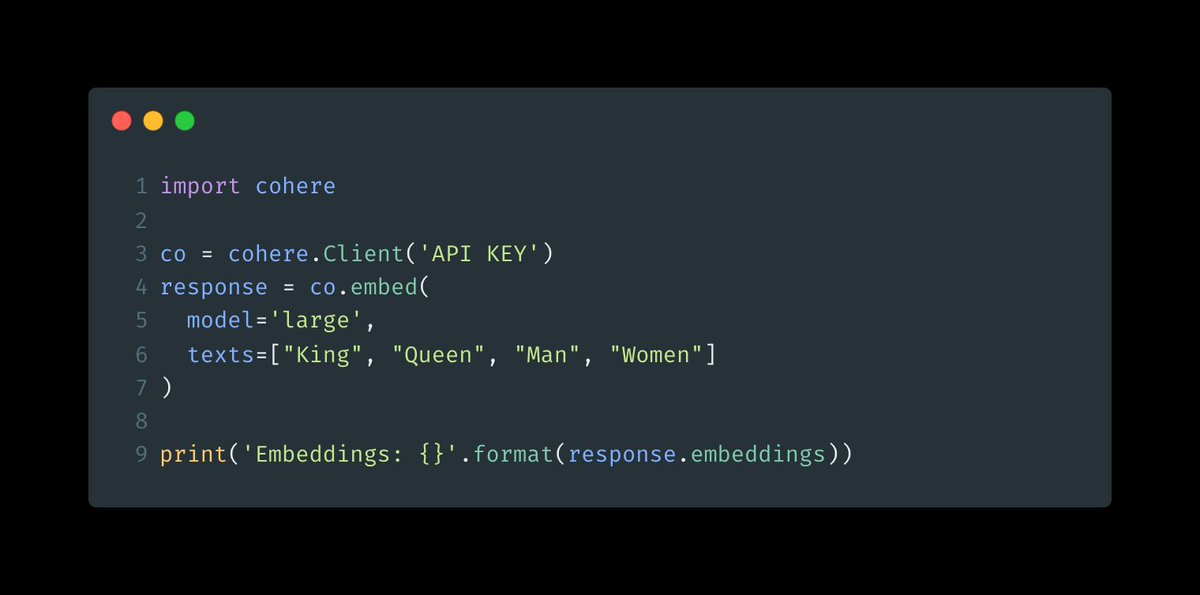
You can use @cohere's word embedding to solve any sort of problem.
When I partnered with them, I started using their playground. You can do everything visually, and it generates the code for you!
To play with it, sign up using this link:
dashboard.cohere.ai/welcome/regist

Santiago
@svpino
I help companies build Machine Learning • I write @0xbnomial • Tweets about what I learn along the way.
Missing some tweets in this thread? Or failed to load images or videos? You can try to .