
这确实是一个相当好的绕过tokens长度限制解决方案,我尝试将这个方案整理一下。


Chuangbo Li@chuangbo
Mar 03 23
View on Twitter
你是否因为 ChatGPT 无法“学习”超过 4096 个 token 的上下文而感到困扰?如果是的话,不妨看看这个开源例子。它的基本原理是,通过 Embedding 模型和数据库在大量物料中搜索可能与用户回答相关的段落,然后从这些段落中生成 prompt,以便 ChatGPT 进行回答。
现在ChatGPT的API是无状态的,意味着你需要自己去维持会话状态,保存上下文,每次请求的时候将之前的历史消息全部发过去,但是这里面有两个问题:1. 请求内容会越来越大;2. 费用很高。
原推的方案可以借助OpenAI的embedding模型和自己的数据库,先在本地搜索数据获得上下文,然后在调用ChatGPT的API的时候,加上本地数据库中的相关内容,这样就可以让ChatGPT从你自己的数据集获得了上下文,再结合ChatGPT自己庞大的数据集给出一个更相关的理想结果。

Mckay Wrigley@mckaywrigley
Mar 02 23
View on Twitter
I embedded all of @Paul Graham’s essays.
All 605,870 tokens worth.
Use OpenAI’s new model to search & chat with them at paul-graham-gpt.vercel.app.
Code & dataset is 100% open-source for anyone to use.
GitHub: github.com/mckaywrigley/p
这种模式尤其适合针对一些特定著作、资料库的搜索和问答。我想之前有人做了模拟乔布斯风格的问答应该也是基于这种模式来做的。
比如@倪爽 想做的将自己的Twitter借助OpenAI整理成知识库,让AI代替自己回复问题,应该就可以基于这个来实现。

倪爽@nishuang
Mar 02 23
View on Twitter
为什么我要下载自己的推文,因为我发现可以自己动手,用 GPT 建立个人知识库
设想一下,如果我把我所有推文、加上我提及的所有设计文章,全部转为可以用自然语言检索的知识库,那么现实一点说,我就创造了一个虚拟的、随时回答你问题、能帮你提高设计水准的设计顾问
浪漫一点说,我就是在“百年之后”之前,先克隆了一各数字版本的我,凭空创造了一个至少还能再活一百年的可交互的灵魂 不过 GPT 按字数计算 token 的收费方式太贵了,我就泄气了…直到昨天 OpenAI 忽然宣布降价十倍
忽然我又可以创造 GPT 的个人知识库了
按照这个发展速度,不出五年,就会有公司推出服务:帮你记录你每天的言行举止,再挖出你以往所有的数字记录,然后帮你创造一个数字版本的克隆人
哄老婆/老公、教小孩、陪宠物、应付亲戚微信群、训斥下属、舔上司屁股……只要是动嘴就能解决的问题,克隆人就能帮你干了
期待 OpenAI 继续十倍十倍地降价
不过 GPT 按字数计算 token 的收费方式太贵了,我就泄气了…直到昨天 OpenAI 忽然宣布降价十倍
忽然我又可以创造 GPT 的个人知识库了
按照这个发展速度,不出五年,就会有公司推出服务:帮你记录你每天的言行举止,再挖出你以往所有的数字记录,然后帮你创造一个数字版本的克隆人
哄老婆/老公、教小孩、陪宠物、应付亲戚微信群、训斥下属、舔上司屁股……只要是动嘴就能解决的问题,克隆人就能帮你干了
期待 OpenAI 继续十倍十倍地降价
不过 GPT 按字数计算 token 的收费方式太贵了,我就泄气了…直到昨天 OpenAI 忽然宣布降价十倍
忽然我又可以创造 GPT 的个人知识库了
按照这个发展速度,不出五年,就会有公司推出服务:帮你记录你每天的言行举止,再挖出你以往所有的数字记录,然后帮你创造一个数字版本的克隆人
哄老婆/老公、教小孩、陪宠物、应付亲戚微信群、训斥下属、舔上司屁股……只要是动嘴就能解决的问题,克隆人就能帮你干了
期待 OpenAI 继续十倍十倍地降价具体解释一下它的实现原理
1. 首先准备好你要用来学习的文本资料,把它变成CSV或者Json这样易于处理的格式,并且分成小块(chunks),每块不要超过8191个Tokens,因为这是OpenAI embeddings模型的输入长度限制

2. 然后用一个程序,分批调用OpenAI embedding的API,目前最新的模式是text-embedding-ada-002,将文本块变成文本数字向量。
参考资料:platform.openai.com/docs/guides/em
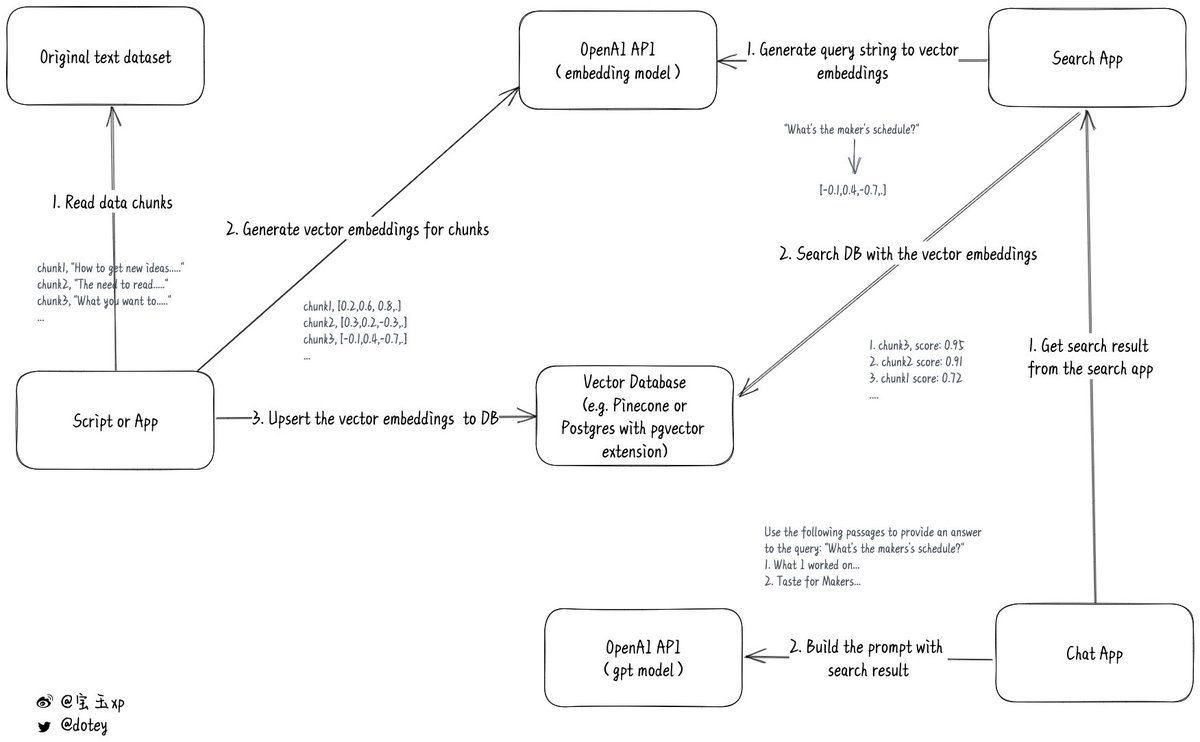
这里简单解释一下,对于OpenAI来说,要判断两段文本的相似度,它需要先将两段文本变成数字向量(vector embeddings),就像一堆坐标轴数字,然后通过数字比较可以得出一个0-1之间的小数,数字越接近1相似度越高。
所以要借助OpenAI检索相似度,将文本编码成数字向量必不可少。

3. 需要将转换后的结果保存到本地数据库。注意一般的关系型数据库是不支持这种向量数据的,必须用特别的数据库,比如Pinecone数据库、Postgres数据库(pgvector 扩展)
保存的时候,需要把原始的文本块和数字向量一起存储,这样才能根据数字向量反向获得原始文本。
有点类似于全文索引中给数据建索引

4. 等需要搜索的时候,先将你的搜索关键字,调用OpenAI embedding的API把关键字变成数字向量。
拿到这个数字向量后,再去自己的数据库进行检索,那么就可以得到一个结果集,这个结果集会根据匹配的相似度有个打分,分越高说明越匹配,这样就可以按照匹配度倒序返回一个相关结果。

5. 聊天问答的实现要稍微复杂一点
当用户提问后,需要先根据提问内容去本地数据库中搜索到一个相关结果集。
然后根据拿到的结果集,将结果集加入到请求ChatGPT的prompt中。

比如说用户提了一个问题:“What's the makers's schedule?”,从数据库中检索到相关的文字段落是:“What I worked on...”和"Taste for Makers...",那么最终的prompt看起来就像这样:

这样ChatGPT在返回结果的时候,就会加上你的数据集,让ChatGPT的回复更有针对性。
项目地址:github.com/mckaywrigley/p


Missing some tweets in this thread? Or failed to load images or videos? You can try to .