
OpenAI 刚刚发布了 GPT-4
GPT-4 是大型多模态模型(large multimodal model),支持图像和文本的输入,并生成文本结果。
这个 thread 会汇总一下有关 GPT-4 的一些信息(包括论文中的一些要点和实际的体验)。

GPT-4 在专业和学术能力的 benchmark 上已经达到了人类水平。
例如模拟律师考试分数占所有应试者的前 10%,而 GPT-3 的测试结果为倒数 10%。
现在想要提前体验的有 2 种方法:
- ChatGPT Plus 订阅(可能不是所有人都有)
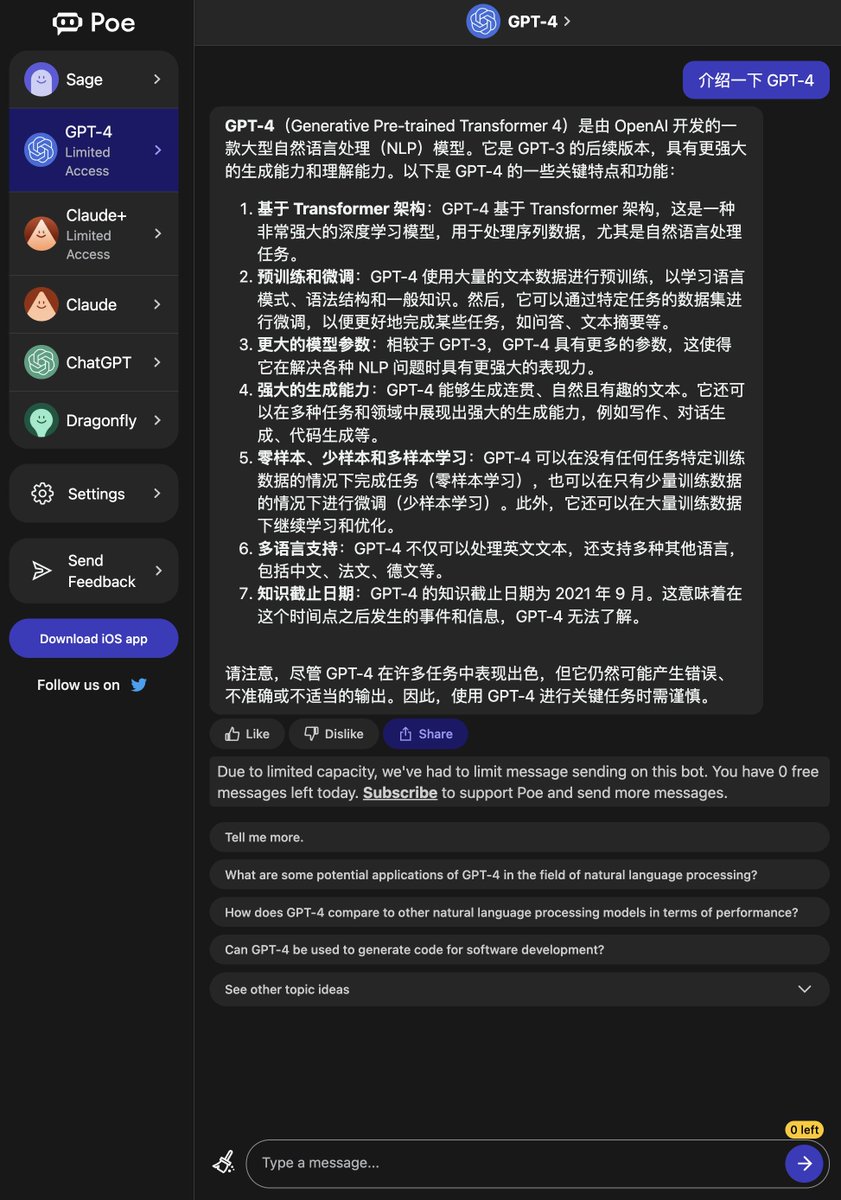
- Poe 中已经集成了 GPT-4(同时集成的还有 Claude+ 这个新的 AI)
GPT-4 演示的直播,还有 2 个小时开始。
youtube.com/watch?v=outcGt
基于 GPT-4 的第一个产品:be my eyes
目前看起来是一个帮助视力障碍人群的辅助工具,可以使用 GPT-4 的多模态能力来识别、解释图片中的内容。
具体介绍  bemyeyes.com
bemyeyes.com
bemyeyes.com作为开发团队,现在可以做的第一件事就是先申请一下 GPT-4 的 API。
openai.com/waitlist/gpt-4

GPT-4 在各种考试中的结果
几个接近满分的测试项目:
- USABO Semifinal 2020(美国生物奥林匹克竞赛)
- GRE Writing
可以看到数据大部分都是好于 GPT-3 的。

GPT-4 现在已经远优于大部分现有的大语言模型了,包括在许多领域上达到了 state-of-the-art (SOTA) 的模型。
Benchmark 的数据

GPT-4 在不同语种上的能力表现
中文的准确度大概在 80% 左右,已经要优于 GPT-3.5 的英文表现了。

官网给了一些使用的样例,这里挑几个有意思的说一下。
第一个可以简单理解为就是解释图片中的内容。

这个例子就有点厉害了,直接通过图片的方式就能够总结论文 

直接让 GPT-4 基于图片中的内容来回答对应的问题。

可以通过 system 参数的方式来定义 AI 的行为(这个在 ChatGPT 中已经支持了)
例如这个例子中就是让 AI 使用苏格拉底的风格来回答问题,不给出具体答案,而是提出问题来帮助学生进行独立思考。

GPT-4 的局限性
虽然现在模型所展示出的功能非常强大,但是与前几代的 GPT 模型存在一些类似的问题,比如生成的结果不符合事实。
在这个方面,GPT-4 的得分要比 GPT-3.5 高 40%。

这个问题联想到了前几天读的 MS Research 的一篇论文:MathPrompter: Mathematical Reasoning using Large Language Models
这篇论文中提到的一个方法是使用 zero shot COT (chain of thought) + verification 的方法来保证数值计算结果的准确性。
arxiv.org/abs/2303.05398

GPT-4 的训练数据和 GPT-3 的貌似差不多,都是截止到 2021 年 9 月。
OpenAI 基于用户规则在 RLHF 上加了一个额外的奖励信号,来减少模型的有害输出。
不确定是否有新的 prompt injection 的方式来进行破解。

现在部分 ChatGPT Plus 的用户已经可以体验到 GPT-4 模型了
1. 使用会有上限,并且根据访问量来控制
2. 可能会引入除 Plus 外的新的订阅级别
API 中使用的模型是:gpt-4-0314
- 需要申请加入 waitlist
- 现在只支持纯文本的请求(图像输入还在 alpha 阶段)
- 定价:prompt - $0.03 per 1k token, completion - $0.06 per 1k token
- context 长度为 8192 tokens,并且提供 32768 token 的版本(价格也更贵,$0.06 & $0.12)
用 GPT-4 来辅助阅读 GPT-4 的论文

GPT-4 论文的 Appendix A.7 节,可以学习一下 OpenAI 是如何写 few-shot prompt 的。




Missing some tweets in this thread? Or failed to load images or videos? You can try to .