Supabase技术文档接入AI搜索后,能支持自然语言,能写代码,甚至能debug,估计很多人好奇它是怎么实现的。
集成ChatGPT的AI文档检索要解决两个问题:1. 检索;2. 对话
比如说如图一所示,我问了一个问题:“如何使用Nextjs连接supalbase, 请用中文回复”
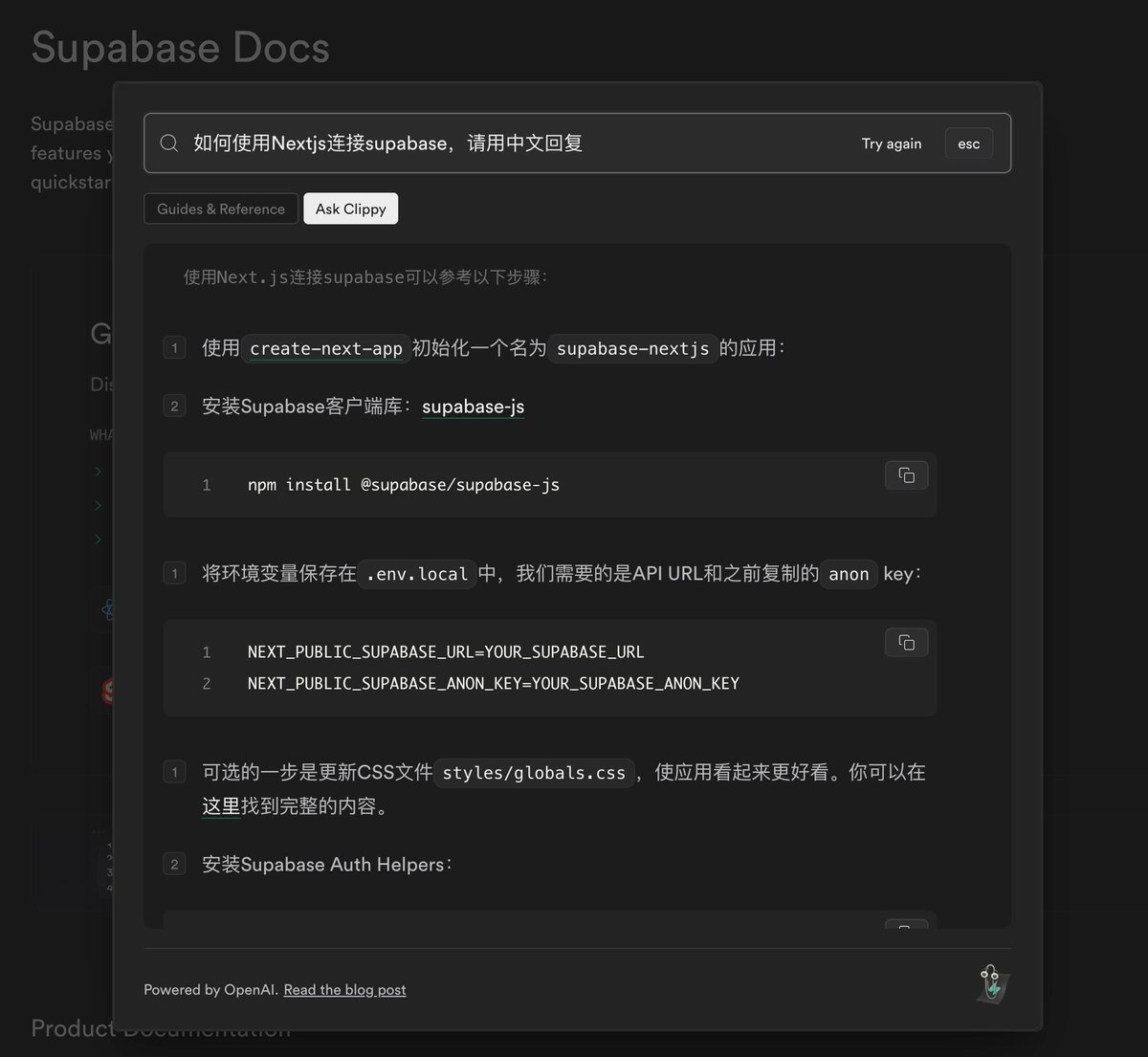
第一步要做的就是把所有满足这个输入条件的文章都找出来。但按照以前全文检索的思路,分词、再查找,几乎不可能,因为原始文档都是英文的,而我输入的是中文,根本无法按照关键字去检索。
这里用的是一种Embeddings的技术,OpenAI针对Embeddings提供了API,输入文本后,可以得到一串数字。
那么什么是Embeddings呢?
Embeddings是用来测量“关联性”的,可以用来:
• 搜索:看你搜索的问题和一组文本的相似度如何
• 建议:两种产品的相似度如何
• 分类:如何对文本进行分类
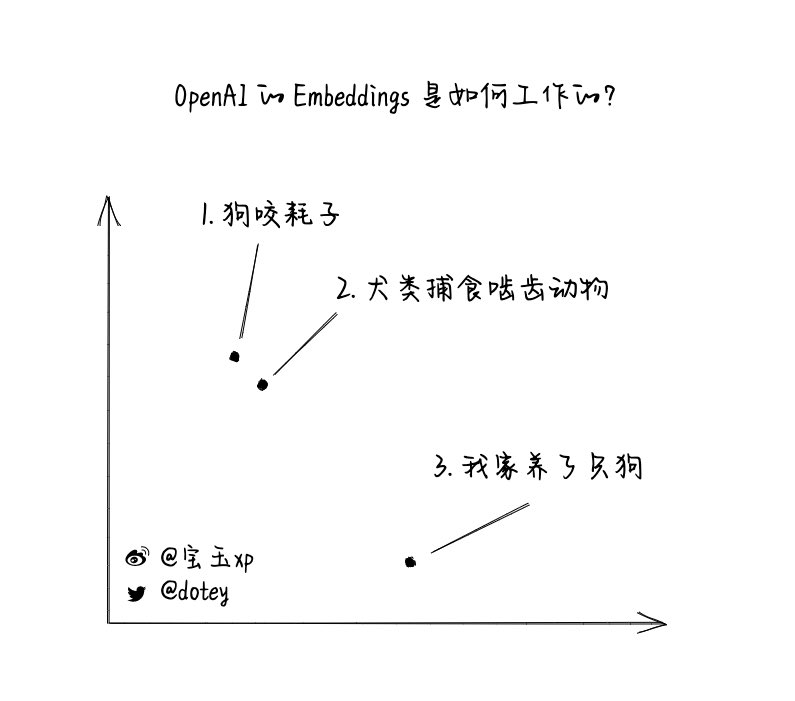
比如说下面有三个短语:
1. "狗咬耗子"
2. "犬类捕食啮齿动物"
3. "我家养了只狗"
那很明显1和2是类似的,即使它们之间没有任何相同的文字。那么怎么让计算机知道1和2很相似呢?
OpenAI 的 Embeddings 是如何工作的?
当然我们不需要关心背后的神经网络模型,Embeddings将文本压缩成分布式的连续值数据(vectors向量)。
如果我们把之前的短语对应的向量能画在坐标轴上,它看起来像图中那样。短句1和短句2会离得很近,而短句3和他们离得比较远。
OpenAI提供了Embeddings的API,可以事先将所有的文档转成文本向量数据,然后将结果存储到支持向量的数据库。如果你数据不大,存成csv文件,然后加载到内存,借助内存搜索也是一样的。具体可以参考Kindle GPT的实现:
x.com/dotey/status/1

宝玉@dotey
Mar 10 23
View on Twitter
将你Kindle上的读书笔记导出,然后你可以针对自己的读书笔记搜索和对话。
从这个项目中,你可以借鉴是如何调用OpenAI Embeddings (text-embedding-ada-002) 来生成embeddings,以及如何搜索生成的结果。
没有用向量数据库,作者写了一个cosSim函数,很小巧,可以直接实现了在内存中对embeddings检索


当用户提问的时候,把用户的问题也借助Embeddings API也变成文本向量,然后使用向量搜索,就能找出来哪些结果是接近的。比如我提的问题,文档中的“Use Supabase with NextJS”就很接近。

借助Embeddings,就能帮助用户检索到想要的结果了。
但这还不够,因为光检索到结果,只能给用户返回文档,而不能按照用户的要求返回中文,甚至生成代码。
这时候就要借助ChatGPT的和prompt了。

ChatGPT是一个AI聊天机器人,它有一个庞大的知识库,它能理解用户的指令,能写代码,但是它对你的文档却一无所知,所以用户在提问时,你需要把匹配到的文档,生成prompt,喂给ChatGPT,让ChatGPT将“用户的问题”、“搜索到的文档”结合自己的知识库,返回给用户最终的结果。
继续以图一中我的问题为例,给ChatGPT的prompt大概长这样:

有了这些信息,就足够ChatGPT帮助你按照Supabase上匹配的文档,给你回复甚至生成代码了。参考文档:supabase.com/blog/openai-em

如果你需要开源的ChatGPT文档检索回复的代码实现,可以参考 gpt3.5-turbo-pgvector 这个项目:
 github.com/gannonh/gpt3.5
github.com/gannonh/gpt3.5
github.com/gannonh/gpt3.5基于embedding和ChatGPT的文档检索原理介绍 twitter-thread.com/t/163726788478
twitter-thread.com/t/163726788478
twitter-thread.com/t/163726788478
宝玉
@dotey
Prompt Engineer, dedicated to learning and disseminating knowledge about AI, software engineering, and engineering management.
Missing some tweets in this thread? Or failed to load images or videos? You can try to .