
Jeremy Howard@jeremyphoward
Apr 28, 2023
16 tweets
I'm seeing a lot of people confused about this - asking: what exactly is the problem here? That's a great question!
Let's use this as a learning opportunity and dig in. 

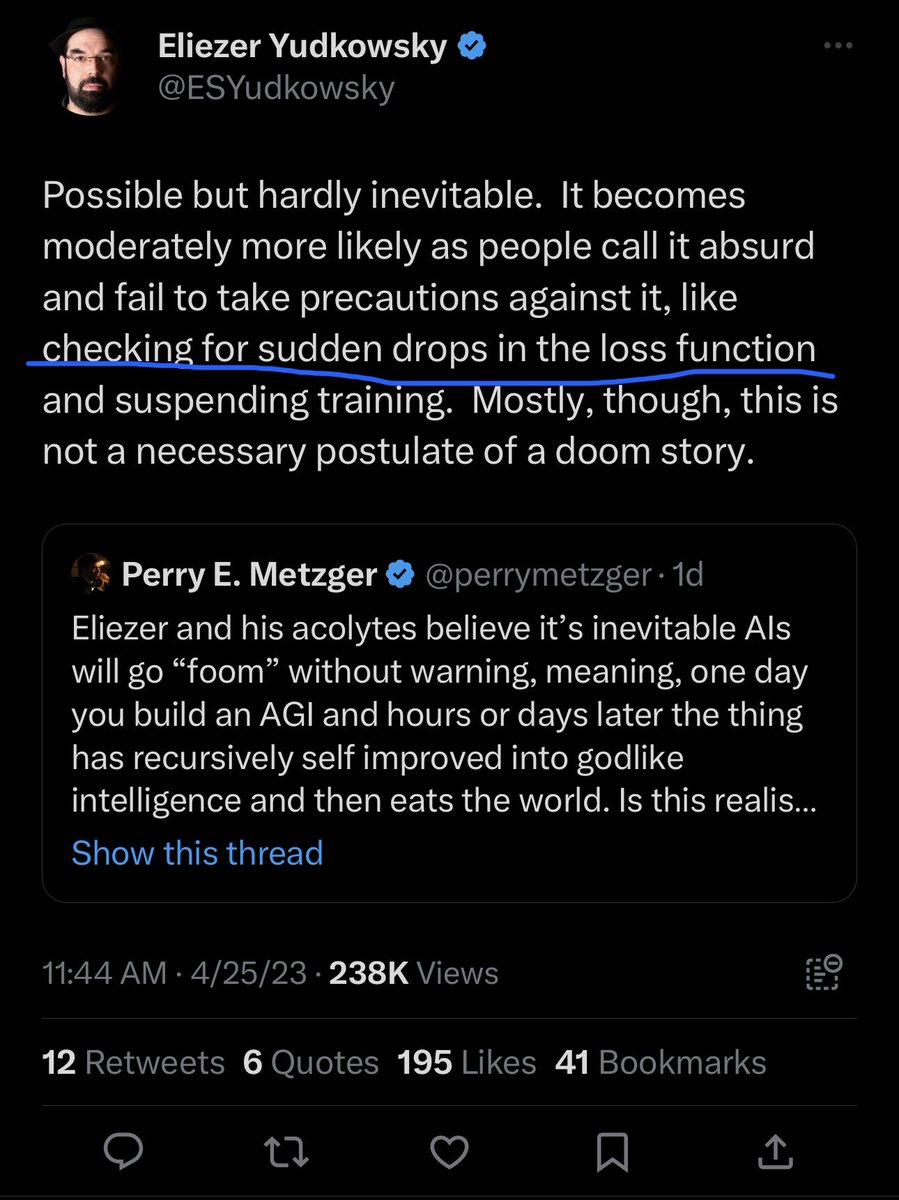
First, I've seen that one of the most common responses is that anyone criticising the original post clearly doesn't understand it and is ignorant of how language models work.
Aidan Gomez is an author of the Transformers paper, and is CEO of Cohere. I think he understands fine.
So why haven't we seen clear explanations of why "checking for sudden drops in the loss function and suspending training" comment is so ludicrous?
Well, the problem is that it's such a bizarre idea that it's not even wrong. It's nonsensical. Which makes it hard to refute.
To understand why, we need to understand how these models work. There are two key steps: training, and inference.
Training a model involves calculating the derivatives of the loss function with respect to the weights, and using those to update the weights to decrease loss.
Inference involves taking a model that has gone through the above process (called "back propagation") many times and then calculating activations from that trained model using new data.
Neither training nor inference can have any immediate impact on the world. They are simply calculating the parameters of a mathematical function, or using those parameters to calculate the result of a function.
Therefore, we don't need to check for sudden drops in the loss function and suspend training, because the training process has no immediate impact on the outside world.
The only time that a model can impact anything is when it's *deployed* - that is, it's made available to people or directly to external systems, being provided data, making calculations, and then those results being used in some way.
So in practice, the way that models are *always* deployed is that after training, they are tested, to see how they operate on new data, and how their outputs work when used in some process.
Now of course, if we'd seen during training that our new model has much lower loss than we've seen before, whilst we wouldn't "suspend training", we would of course check the model's practical performance extra carefully. After all, maybe it was a bug? Or maybe it's more capable?
But saying "we should test our trained models before deploying them" is telling no-one anything new whatsoever. We all know that, and we all do that.
Figuring out better ways to test models before deployment is an active and rich research area.
OTOH, "check for sudden drops in the loss function and suspend training" sounds much more exciting.
Problem is, it's not connected with the real world at all.
Some folks have pointed out that "drops in the loss function" is a pretty odd way to phrase things. It's actually just "drops in the loss".
An AI researcher saying "drops in the loss function" is a bit like a banker saying "ATM machine" - maybe a slip, maybe incompetence.
PS: please don't respond to this thread with "OK the exact words don't make sense, but if we wave our hands we can imagine he really meant some different set of words that if we squint kinda do make sense".
I don't know why some folks respond like this *every* *single* *time*.
PPS: None of this is to make any claim as to the urgency or importance of working on AI alignment. However, if you believe AI alignment is important work, I hope you'll agree that it's worth discussing with intellectual rigor and with a firm grounding of basic principals.
*principles

Jeremy Howard
@jeremyphoward
🇦🇺 Co-founder: @AnswerDotAI & @FastDotAI ;
Prev: professor @ UQ; Stanford fellow; @kaggle president; @fastmail/@enlitic/etc founder
https://t.co/16UBFTX7mo
Missing some tweets in this thread? Or failed to load images or videos? You can try to .