
Tim Dettmers@Tim_Dettmers
May 24, 2023
41 tweets
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
Paper: arxiv.org/abs/2305.14314
Code+Demo: github.com/artidoro/qlora
Samples: colab.research.google.com/drive/1kK6xasH
Colab: colab.research.google.com/drive/17XEqL1J

Want to see how good Guanaco 65B is? Here is a little fun game: Can you distinguish ChatGPT outputs from Guanaco-65B outputs? We authors had a hard time distinguishing them — maybe there is a trick? Are you better than us? colab.research.google.com/drive/1kK6xasH (solutions after each sample)

Rapid-fire-findings (1/3):
- 97% ChatGPT performance on 1 consumer GPU in 12 hours
- matching 16-bit performance across all scales and models
- key contributions: NormalFloat data type, paged optimizers, double quantization
- FLAN v2 good for instruction tuning, bad for chatbots
Rapid-fire-findings (2/3):
- data quality >> data quantity: a 9000 dataset beat a 1M dataset
- The Open Assistant dataset is high quality -> Guanaco
- Guanaco beats ChatGPT in a competition on the Vicuna benchmark as judged by both humans and GPT-4
- Vicuna benchmark is too small
Rapid-fire-findings (3/3):
- we create a new benchmark on Open Assistant data (10x Vicuna), and it appears to be more reliable
- we gather failure cases for Guanaco: it is bad at math, good for suggested misinformation and theory of mind
With QLoRA you can finetune Guanaco 33B/65B models on a single 24/48GB GPU taking only 12/24h for a finetuning run. QLoRA replicates 16-bit performance across the board in all scenarios and scales tested.

"But is fine-tuning with LoRA not worse compared to full-finetuning?"
It is true that regular LoRA does not perform well. The magic that we apply is hyperparameter tuning  If you attach LoRA to all linear layers, it turns out it works super well with no issues at all.
If you attach LoRA to all linear layers, it turns out it works super well with no issues at all.
If you attach LoRA to all linear layers, it turns out it works super well with no issues at all. 
How does QLoRA work? It combines a frozen 4-bit base model with adapters on top. We backpropagate through the 4-bit weights into the adapters. We invent some neat tricks for memory efficiency. The main components are: 4-bit NormalFloat, Paged Optimizers, and Double Quantization.

Let's do a deep dive! 4-bit NormalFloat is a new data type and a key ingredient to maintaining 16-bit performance levels. Its main property is this: Any bit combination in the data type, e.g. 0011 or 0101, gets assigned an equal number of elements from an input tensor.
This means the data type is information-theoretically optimal similar to Huffman coding (does not guarantee the best error). How do we create this data type for neural networks? We can exploit one property of trained neural networks: their weights are normally distributed.
To find a quantization with the same number of values in each quantization bin, we want to dissect the distribution of the tensor so that when plotted, each distribution slice has equal area (area = amount of numbers in a bin). Here a visualization:
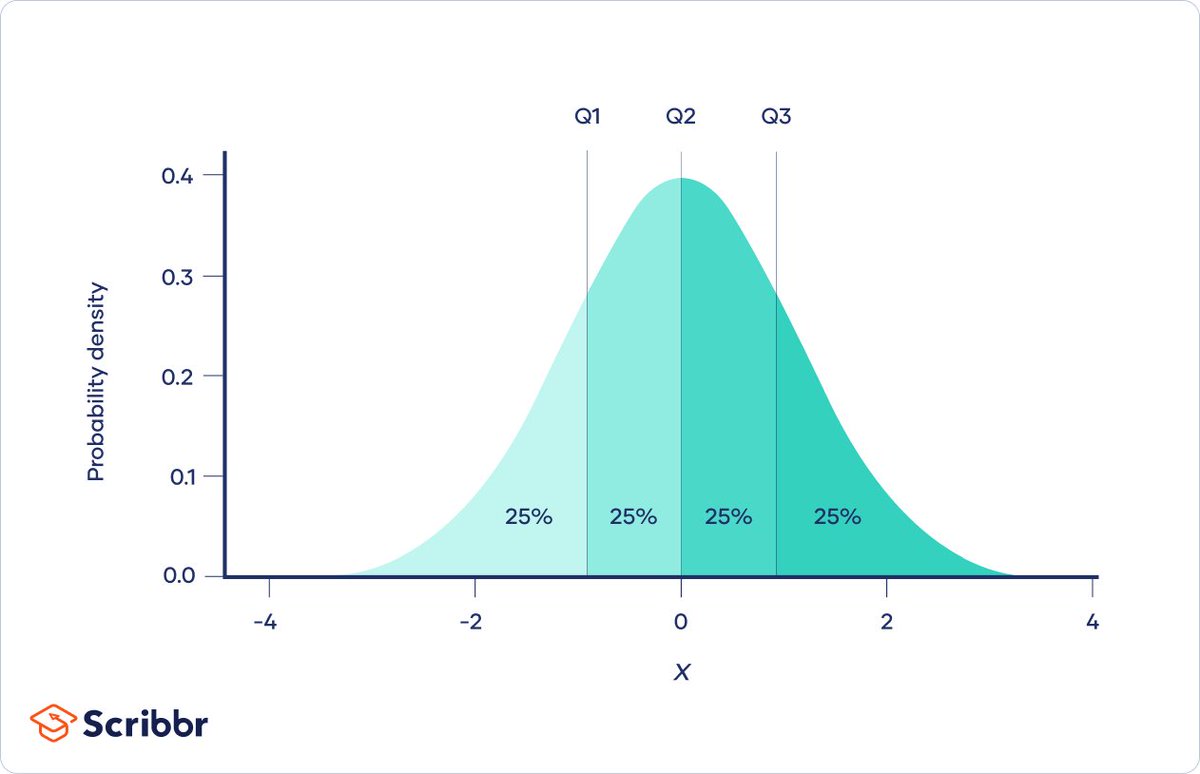
It this theoretically optimal data type good in practice? Yes, it is. Bit-for-bit it yields more zero-shot accuracy compared to a Float data type. In this plot you also see DQ = Double Quantization. What is that?

Double quantization is very simple but also silly: If we want to make our first quantization from 16-bit -> 4-bit more efficient, we can do another quantization on top of it. In this case, the 2nd quantization quantized the quantization constants (say that 5x really fast)
With this trick, we can use a small block size (important for good 4-bit performance) and reduce the overhead of small blocks from 0.5 bits per parameter to just 0.125 bits per parameter.
The final trick is paged optimizers. I implemented this actually a year ago but could not find a use for it. It is similar to optimizer offloading in that some part of the optimizer lives on the CPU and some part on the GPU, and exchange happens if an optimizer update occurs.
The difference between offloading and paging is significant: offloading is lazy and 100% out-of-memory-proof. While offloading needs to be managed manually, paged optimizer offloads small pages automatically in the background. They are prefetched to the GPU before being needed.
The other advantage is paged optimizers are adaptive: If you have enough memory, everything stays on the GPU and is fast. If you hit a large mini-batch, the optimizer is evicted to the CPU and returned to the GPU later. Thus paged optimizers are perfect for surviving mem spikes
Together, these techniques make fitting large models into small GPUs easy. With QLoRA, finetuning was so effective that we could finetune more than 100 LLaMAs daily on the small GPU cluster at University of Washington. We decided to use this to make a super in-depth analysis.
Our main finding here: (1) instruction tuning datasets are good for instruction following but bad for chatbot performance; (2) you can create a 99.3% of ChatGPT performance level chatbot with QLoRA in just 24 hours of fine-tuning!
First things first: We did fine-tune all commonly used instruction-following datasets. The results: some datasets are bad, and some are good. FLAN v2 is best to get good scores for instruction-following.

The surprise comes, though, when we train chatbots and find that FLAN v2 is by far the worst chatbot. What is going on? Well it seems to be as simple as "you are good at what you fine-tune for". FLAN v2 was designed for "reasoning" and related capabilities but not for chatting.

What is data that was designed for chatbot interactions: The Open Assistant dataset is one of the most high-quality datasets here. Carefully validated by the community, multi-lingual, and the interesting thing, although tiny (9000 samples in our case), it packs a huge punch!
FLAN v2 has more than 1M instruction following examples while the Open Assistant data has only 9000 samples. The performance difference shows: high-quality data matters for fine-tuned performance more than the number of samples. (Nice ablation on this in our appendix)
So our Guanaco recipe is as simple as OpenAssistant data + QLoRA. With this, we create 7/13/33/65B chatbots. These chatbots are surprisingly powerful. In a tournament-style competition against other models, both humans and GPT-4 think Guanaco is better than ChatGPT.
Our setup: models get a prompt and compete to produce the best response. A judge (GPT-4/humans) determines the winner. The winner gets Elo points relative to the opponent's strength, and the loser loses points. Over time, Elo scores reflect skill at this game. Higher is better.

he problem with this setup is that 80 prompts is not much and can introduce bias and uncertainty. So we replicated out experiment with GPT-4 judges on the Open Assistant dataset creating the "Open Assistant benchmark," which seems to be much more reliable.

We saw that our model was pretty good. So we did the natural think, we tried to break it  . It was not quite easy, Guanaco seems to be pretty robust to suggested misinformation and theory of mind where other models fail. But it has its weaknesses.
. It was not quite easy, Guanaco seems to be pretty robust to suggested misinformation and theory of mind where other models fail. But it has its weaknesses.
. It was not quite easy, Guanaco seems to be pretty robust to suggested misinformation and theory of mind where other models fail. But it has its weaknesses. 
We see random refusals:

Its easy to get information that Guanaco was told to keep secret

Its really bad at math:


There are many limitations with the paper, for example, we did not do a thorough analysis on biases. We benchmarked on the CrowS bias benchmark where Guanaco did well, but there might be many hidden severe biases that remain uncovered.

The other main limitation is that, currently, 4-bit inference is slow. I did not have the time to finish 4-bit inference kernels; they need more work. Apparently, it is really difficult to write CUDA code for matrix multiplication with a data type not supported by hardware. Oops!
With QLoRA, the outlook is very bright! Many researchers were depressed when I talked to them after ChatGPT and GPT-4. I, on the other hand, have never been more excited about working in academia! You can do so many things with QLoRA and LLaMA models. The opportunity are endless!
QLoRA will also enable privacy-preserving fine-tuning on your phone. We estimate that you can fine-tune 3 million words each night with an iPhone 12 Plus. This means, soon we will have LLMs on phones which are specialized for each individual app.
With pretraining out of the way and finetuning super cheap, we have a chance to bring useful things to everyone and also understand what these powerful models are capable of and where they fail. There will be hurdles and dangers, but I am sure we can manage and overcome them.
A year ago, it was a common sentiment that all important research is done in industrial AI labs. I think this is no longer true. Pretraining can only be done with large compute, but there is no need to go for AGI. LLaMA is good enough for understanding and developing better tools
In the next weeks, I will focus on bitsandbytes. I have a draft for 4-bit inference and will integrate that soon. Inference should be 8-16x faster than currently. You should see bug fixes and improvements each day (that is after I caught up on emails and graded class projects).
I want to thank my awesome collaborators @Artidoro Pagnoni @Ari Holtzman @Luke Zettlemoyer . And a special thanks to @younes for helping with the transformers integration and much more! Thank you to all our beta testers! It helped a lot to make the software stable
We also want to thank the @Hugging Face team for their support! They sponsored a 33B Guanaco demo that you can access here: huggingface.co/spaces/timdett (it is a bit slow, but it works).
We are working on a faster demo, but it needs a bit more time.

Further artifacts (datasets) and details are coming soon!
This is the fast demo sponsored by @Hugging Face. Thank you so much! huggingface.co/spaces/uwnlp/g


Tim Dettmers
@Tim_Dettmers
PhD Student at @UW. I blog about deep learning and PhD life at https://t.co/Y78KDJKdtF.
Missing some tweets in this thread? Or failed to load images or videos? You can try to .