
Llama2发布了,这版本可以商用了,我详细整理了一些已知的信息:
- Llama2 的性能和参数
- 如何使用和限制条件
- Llama2 的模型架构
- Llama2 的训练方法论
 下面是详细的信息
下面是详细的信息
下面是详细的信息 
Llama2 的性能和参数
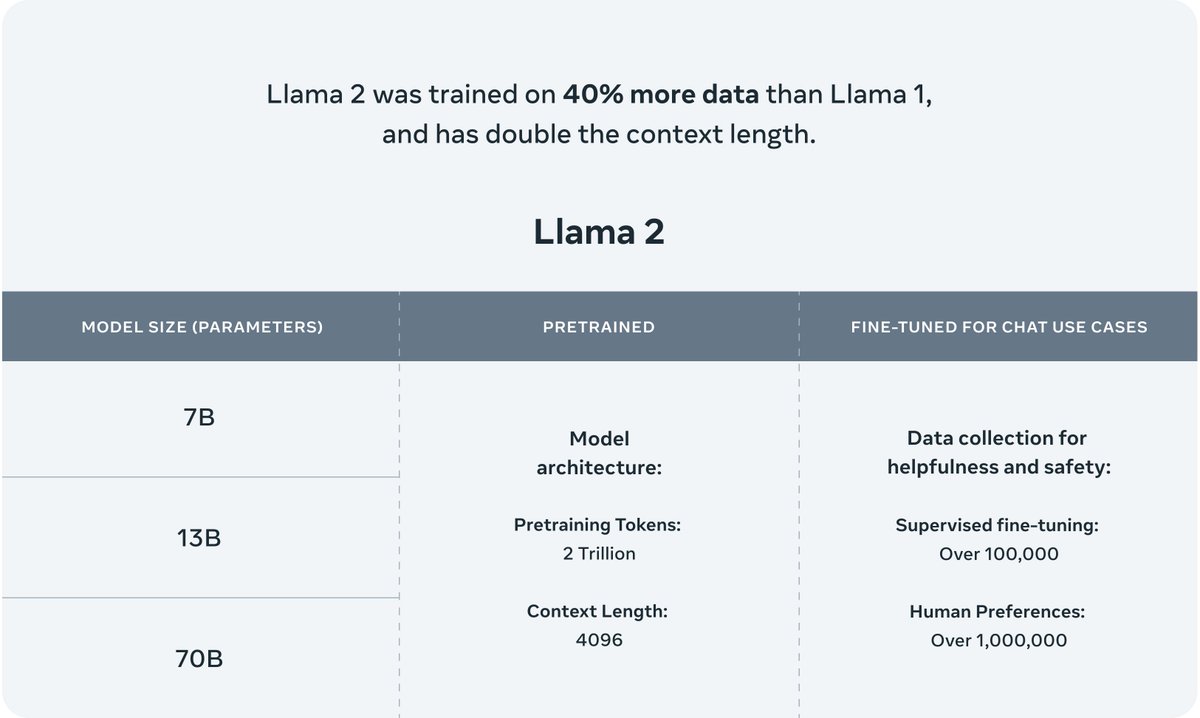
- Llama2有三个大小的版本分别是7B 13B和70B
- Llama 2 的训练数据比 Llama 1 多 40%,上下文长度是 Llama 1 的两倍。
- 预训练的Token为2 万亿,上下文长度为4096
- 据Meta所说,Llama 2 在许多外部基准测试中都优于其他开源语言模型,包括推理、编码、熟练程度和知识测试。

如何使用和限制条件
- 与第一次泄漏的版本不同,这次Meta开放了商业使用的权限。
- 现在可以直接在这个页面申请下载模型:ai.meta.com/resources/mode
- 日活大于7亿的产品需要单独申请商用权限
- 不得使用 Llama 材料或 Llama 材料的任何输出或结果来改进任何其他大型语言模型。

Llama2 的模型架构
- Llama 2-Chat 的基础是 Llama 2 系列预训练语言模型。Llama 2 使用标准的Transformer架构。
- Llama 2-Chat 通过监督微调和强化学习人类反馈进行了优化。先进行监督微调,然后应用包括拒绝采样和PPO在内的强化学习算法进行迭代改进。
- 采用了一些优化,比如预规范化、SwiGLU激活函数和旋转位置嵌入(RoPE)。
- Llama 2-Chat有70亿、34亿、13亿和7亿参数的版本。训练使用公开可获得的数据,没有使用任何Meta用户数据。
Llama2 的训练方法论
1. 预训练
• 使用公开可获得的在线数据进行预训练,总计2万亿个标记。
• 对数据进行了清洗,移除了一些包含大量个人信息的网站。
• 采用标准的Transformer架构,以及一些优化如RoPE等。
2. 监督微调
• 使用高质量的人工标注数据(约3万示例)进行监督微调。
• 优化回答标记,而不是提示标记。
3. 基于人类反馈的强化学习
• 收集人类偏好数据: letting人类比较并选择更好的回复。
• 训练奖励模型,给回复打分。
• 使用拒绝抽样和PPO算法进行迭代调优。
4. 安全性
• 收集安全/有帮助的数据进行监督微调。
• 训练独立的安全性奖励模型。
• 使用内容蒸馏等方法增强安全性。
5. 评估
• 在4K提示上进行有用性人类评估,与ChatGPT等旗鼓相当。
• 在2K提示上进行安全性人类评估,优于多个基准模型。


Missing some tweets in this thread? Or failed to load images or videos? You can try to .