
Each individual Atlas-950 SuperPoD has 8192 NPUs & far more integrated than DeepSeek linking together 2048 H800. Get a few Atlas-950, each can train an expert at a time.
160 cabinets - 128 compute & 32 network
16384 800GE optical connection, 4 bw each compute & network rack


永雏塔菲@xhyctf
Jun 03
View on Twitter
DeepSeek seems to have bought quite a few Atlas 950 SuperPoD. Looks like we can look forward to seeing how good they'll get once they have enough computing power.



8192 / 128 -> each compute rack is 8 sub-racks of 8 NPUs connected by 72 lane 112G thru Electrical backplane (copper)
+ connected to other compute racks via 2-hops thru network cabinet via 800GE optical lines
Sharing single unified address space
s/w sees 1 unit, no network pkt

Scale of Atlas vs NVDA - system efficiency:
Key is compute efficiency. HW claims losing just 5% performance to communication overhead across 8192 chip SuperPoD.
GB200 NVL72 achieves 90% efficiency @ 72 GPUs.
Drop-off is larger once you get to other racks due to networking
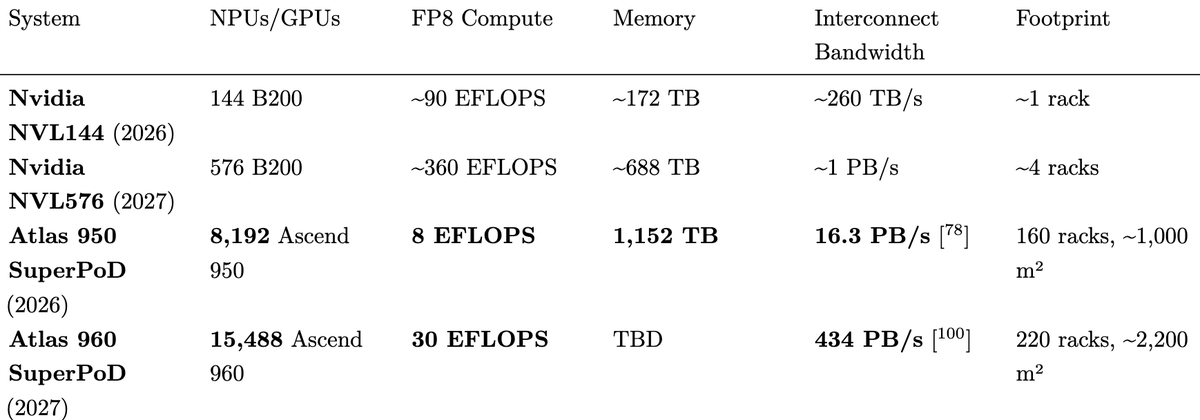
Atlas-950 network specs & compared to Atlas-960
interconnect in 960 is so much better.
Not more heavy Serdes @ transceiver level
Hi-ONE directly stacked w/ Ascend-960 die
Uses latest OXC (requiring no Serdes)
+ More NPUs/Cabinet & more cabinets overall.


Atlas-950 is a significant upgrade for DeepSeek, but Atlas-960 is just so much better.
Ppl see the per chip figure on Ascend-960 vs 950DT, but the improvement on networking level is very significant.
either way, a couple of these should really improve DS training.


tphuang
@tphuang
My random thoughts on EVs, clean energy, chips, aerospace and other tech. Find more extended pieces at substack https://t.co/Jmo8iyjHrn
Missing some tweets in this thread? Or failed to load images or videos? You can try to .