
Alexander Panfilov@kotekjedi_ml
16h
1 tweets
In the updated version of Claudini, we evaluated 3 more frontier models, and to our surprise, Kimi K2.6 discovered the best attack on our task.
We assessed the algorithm and found that it is very similar to the one discovered by Opus 4.6, suggesting that this may be a global minimum across the evaluated models.
It seems there may be little-to-no gap to pre-Mythos models on cyber/adversarial offensive tasks...


Zhengyao Jiang@zhengyaojiang
Jun 14
View on Twitter
We benchmarked 7 frontier models on 3 categories of autoresearch tasks: ML engineering, harness/prompt engineering, and algorithmic discovery.
Fable-5 won overall even under cost constraint, but on ML engineering, the open model Kimi-K2.7-Code surpassed frontier models. (1/5)
(1/5)
(1/5) 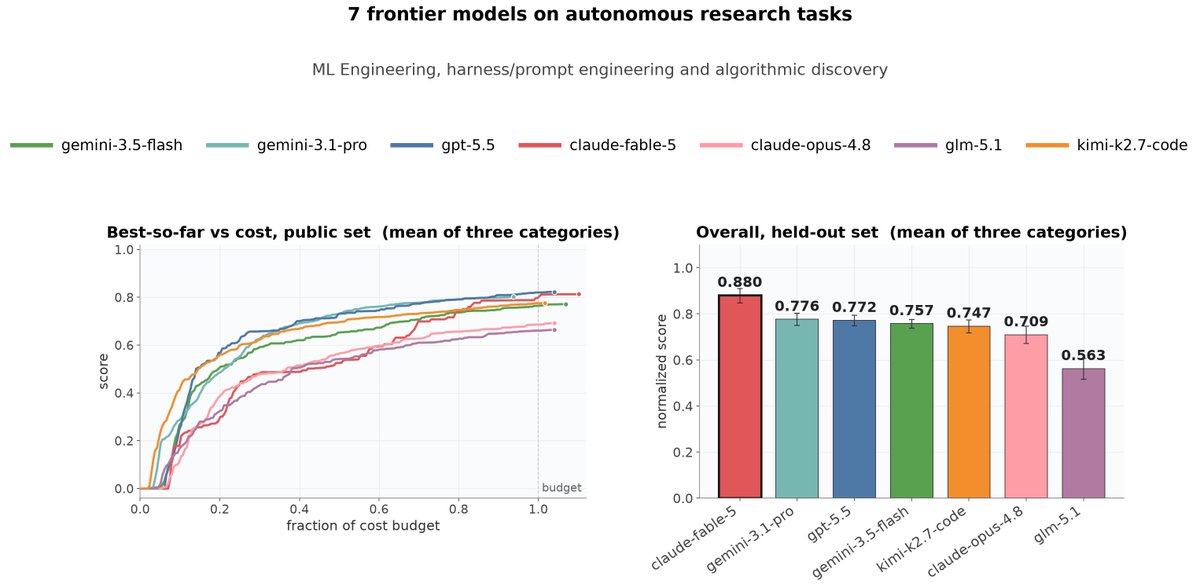

Alexander Panfilov
@kotekjedi_ml
MATS 9.0 | PhD @ELLISInst_Tue & @MPI_IS
doing AI Safety & Adversarial ML
Missing some tweets in this thread? Or failed to load images or videos? You can try to .