Supabase technical documentation access to AI search, can support natural language, can write code, and even debug, I guess many people are curious about how it is achieved. https://t.co/WRumhepdR6
AI document search integrated with ChatGPT has to solve two problems: 1. search; 2. conversation
For example, as shown in Figure 1, I asked a question: "How to use Nextjs to connect to supalbase, please reply in Chinese" https://t.co/RYcplMC56w
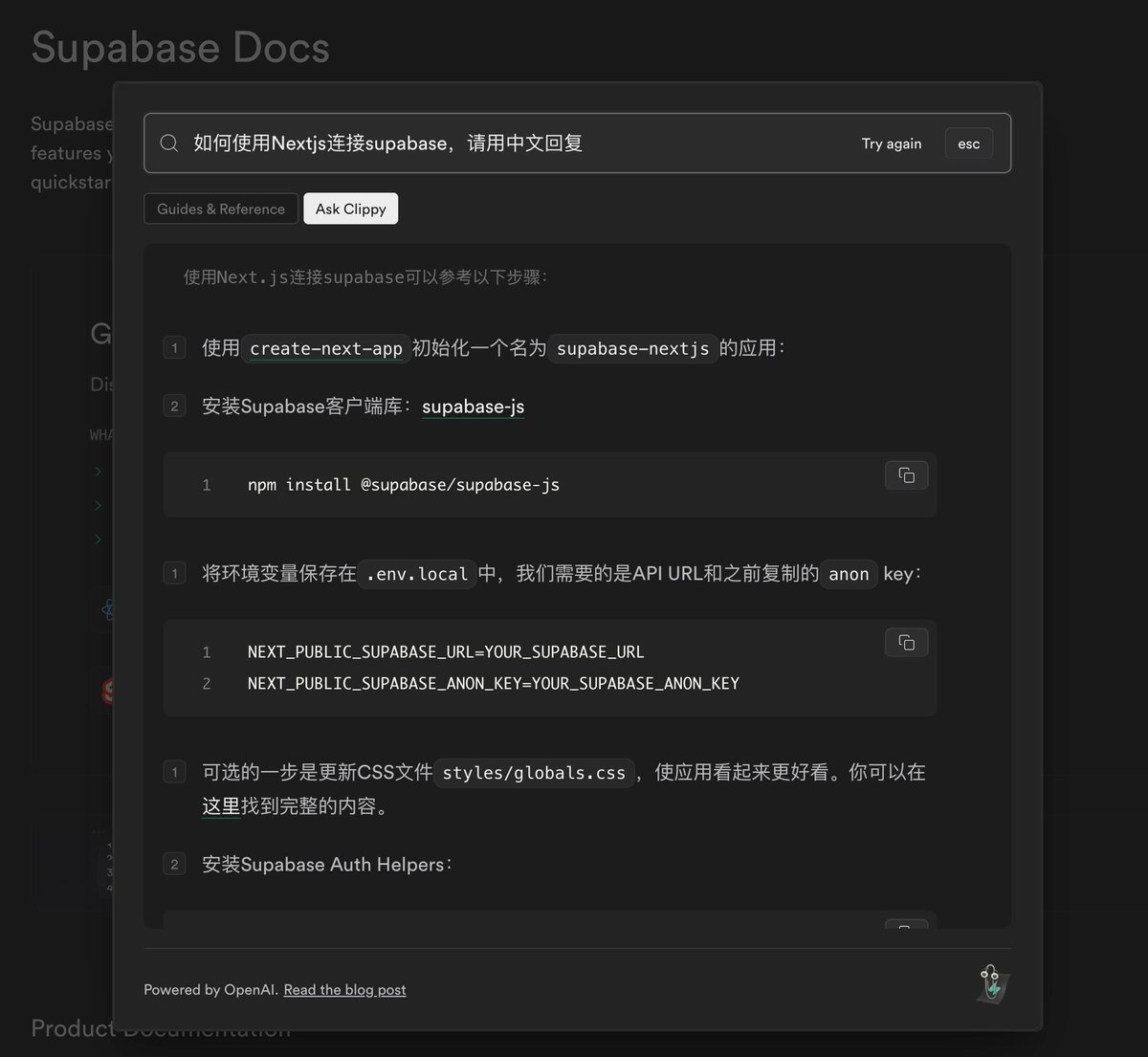
The first step to do is to find all the articles that satisfy this input condition.But following the previous idea of full-text search, splitting words and finding them again, is almost impossible because the original documents are all in English, and what I entered is in Chinese, so it is impossible to search by keywords.
Here a technology of Embeddings is used. OpenAI provides API for Embeddings, and after entering the text, you can get a string of numbers.
So what is Embeddings?
Embeddings are used to measure "relevance" and can be used to
- Search: see how similar the question you are searching for is to a set of texts
- Suggestions: how similar two products are
- Classification: how to classify the text
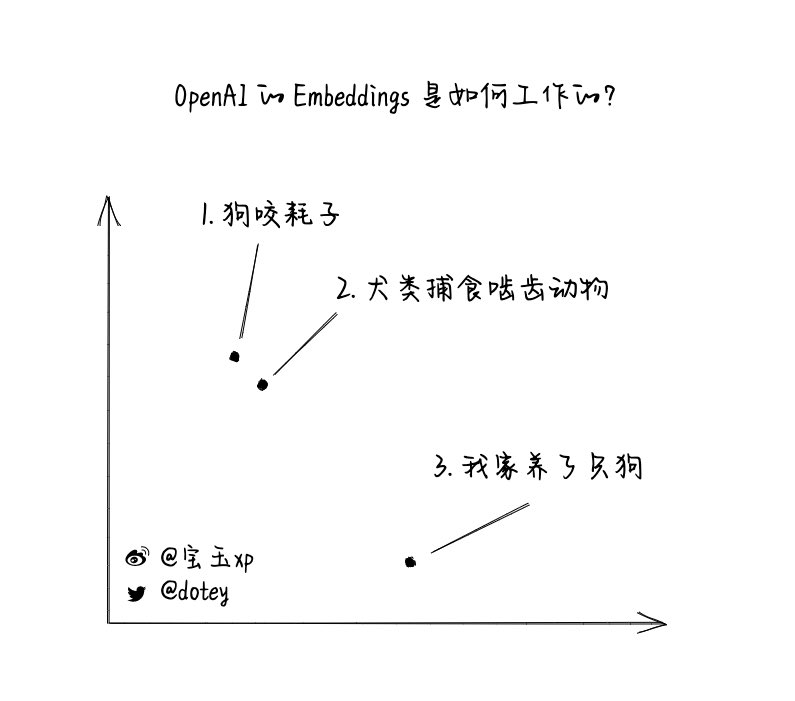
For example, here are three phrases:
1. "Dogs bite rats"
2. "Canines prey on rodents"
3. "My family has a dog"
Then obviously 1 and 2 are similar, even though they don't have any of the same words between them.So how do you get the computer to know that 1 and 2 are similar?
How does OpenAI's Embeddings work?
Of course we don't need to care about the neural network model behind it, Embeddings compresses text into distributed continuous-valued data (vectors vector).
If we plot the vector energy corresponding to the previous phrases on the axes, it looks like in the figure.Phrase 1 and phrase 2 would be close to each other, while phrase 3 is farther away from them. https://t.co/odONClm19k
OpenAI provides the Embeddings API to convert all documents into text vector data beforehand, and then store the results into a database that supports vectors.If your data is not large, save it as a csv file and then load it into memory, with the help of memory search is also the same.For details, see the Kindle GPT implementation at
https://t.co/9gy6nmTn5B

宝玉@dotey
Mar 10 23
View on Twitter
Export the reading notes on your Kindle, and then you can search and talk to them for your own reading notes.
From this project, you can learn how to call OpenAI Embeddings (text-embedding-ada-002) to generate embeddings, and how to search the generated results.
Instead of using a vector database, the authors wrote a cosSim function, which is very small and enables direct in-memory retrieval of embeddings https://t.co/bDsts0gejj https://t.co/4UYsN48cij


When the user asks a question, the user's question is also turned into a text vector with the help of the Embeddings API as well, and then using vector search, you can find out which results are close.For example, for the question I asked, the document "Use Supabase with NextJS" is very close. https://t.co/l2w2LIM447

With the help of Embeddings, it helps the user to retrieve the desired results.
But this is not enough, because the light retrieval of results can only return the user to the document, but not according to the user's requirements to return to Chinese, or even generate code.
This time we have to use ChatGPT's and prompt. https://t.co/xF8YOQhRZ5

ChatGPT is an AI chatbot, it has a huge knowledge base, it can understand the user's instructions, can write code, but it knows nothing about your documents, so when the user asks a question, you need to take the matched documents, generate the prompt, and feed it to ChatGPT, so that ChatGPT will "user's question", "searched documents" combined with their own knowledge base, and return to the user the final result.
Continuing with the example of my question in Figure 1, the prompt to ChatGPT would look like this: https://t.co/ZIfHPR5pHP

With this information, it is enough for ChatGPT to help you reply or even generate code according to the matching documents on Supabase.Reference documentation: https://t.co/1jKA6pCFDs
If you need an open source code implementation of ChatGPT document retrieval responses, you can refer to the gpt3.5-turbo-pgvector project at
🔗 https://t.co/hMrbbFswHy
embedding and ChatGPT-based document retrieval principles introduced 🧵 https://t.co/e0p0Nvb1kL

Translations:English
Missing some tweets in this thread? Or failed to load images or videos? You can try to .